My Notes from Fosdem & Config Management Camp
Sup! It’s been a while.
So, both Fosdem and Config Management Camp conferences are back offline. Thus, I’ve spent a long weekend at my usual Belgian conferences.
Here I want to share some notes with you from the talks I attended. I’m lazy, so I didn’t take notes in real-time. On one hand, this may be a reason these notes be not super accurate. On another hand, I had some time to digest the content and only share things that resonate with me.
Also, I will share only the talks I attended. Not all of them, though, because some were meh. Keep in mind that there was much more content at the conferences. For example, I missed the entire CI/CD track at Fosdem, because I’m too dumb to read the schedule. Plus, there were some talks in other rooms at the same time.
Fosdem 2023 [Saturday 4th of Feb]
Drawing your Kubernetes cluster the right way. How to present the cluster without scaring people [Containers devroom]
Nice talk on how to draw diagrams for complicated systems with Kubernetes as an example.
Key points:
- Prefer multiple simpler diagrams instead of a single complex one.
- Use colors (leverage a color wheel to gain the best contrast).
- Do not overload the diagrams with icons. Icons are not universally readable.
- Do not overload a diagram with arrows if it’s not necessary.
Recipes for reducing cognitive load. yet another idiomatic Go talk [Go devroom]
Very nice presentation about how to write better code in Go. Some things may sound trivial, but it’s important to remind people of basic things from time to time.
Key points on how to make your code better:
- Respect the line of sight. Ideally, your Go code has to have only 2 indentation levels: golden path and error handling. For me, this was a very powerful point. I have even recalled some code that I need to refactor once I’m back to work.
- Avoid too generic packages.
Utilspackage is evil. Ideally, the package name has to provide some context on what this package does. - Work with errors as types because they are.
- Try to keep business logic in pure functions because they are easier to test.
- Read the configuration once and pass it where it’s needed. Do not read environment variables in multiple places in your code.
- Avoid bare booleans, replace them with named constants. There are code examples in the slides, I don’t want to copy them here.
- Go doesn’t have method overloading, but in some cases, you can use functional options to make your code DRYer.
- Prefer functions over methods because they’re easier to test and reuse
- If a function doesn’t change an object, pass it as a value, not a pointer. It will make your code less error-prone.
- Keep logic in synchronous functions, they’re easier to test.
- Functions should not lie. If have a
Delete()function it should delete something or return an error. See the slides & the video for more details. - Optimize the readability. Ideally, one should read your code as a newspaper. Put public functions and methods on top of your file. Split a package into multiple files when it makes sense.
Debugging concurrency programs in Go
To be honest, I am not that experienced Go developer to comprehend this entire talk. One of my takeaways is to use a debugger more often.
Key points:
- Debugging concurrent programs is not that easy. Never assume a particular execution order.
- Implement concurrency on the highest possible level.
- You can add some color to your
goroutinelogs or visualize them in another way. - Use a debugger (duh!).
- You can set breakpoints inside goroutines.
- Run your programs with
-raceflag in test environments to catch possible race conditions. It won’t catch everything but still might be helpful. - Low-level tools like
stracemay help you if all other methods failed.
Five Steps to Make Your Go Code Faster & More Efficient
An easy-to-follow algorithm to make your applications more efficient. Moreover, you can apply some of those points not only to Go.
Key points:
- Follow the TFBO approach: Test => Fix => Benchmark => Optimize.
- Use
go test -benchto run benchmarks several times to ensure that the impact of external factors such as CPU throttling is not significant. - Set clear goals before you start optimization. Sometimes, it’s perfectly fine for your program to be a little bit sluggish. Without clear goals, you will fall into the so-called “premature optimization” pitfall.
- Use profiler, for example
pprofpackage. - Understand, what’s going on under the hood of your app. Sometimes, methods of the standard library are too generic to be optimal for your cause.
Kubernetes and Checkpoint/Restore
This is upcoming functionality in Kubernetes that allows you to checkpoint and restore containers. For example, you will be able to move a container to another node or pause/resume it on the same node without losing the state in memory.
If you run jobs in Kubernetes, you know how cool is it! Especially, if those are long-running jobs that don’t have checkpoints implemented on their own.
Check out the slides and the video for more information and a demo.
Safer containers through system call interception
This talk was about LXD containers and AppArmor. If you run LXD, it may interest you. But, I never saw LXD containers in the wild, to be honest.
Automating secret rotation in Kubernetes
A talk on how to use tools such as Kubernetes External Secret Operator and Reloader to automatically rotate secrets in your cluster with a demo.
We are using Banzai Bank-Vaults for this. Practically speaking this talk was not very useful for me, but still, it was good. Also, I can see some advantages of the approach proposed there.
From a database in a container to DBaaS on Kubernetes
Check this out, if you run databases in Kubernetes.
Key points:
- It’s Ok to run DBs in K8s, more and more people are doing it already.
- Kubernetes operators for DBs are (mostly) fine. Also, it’s beneficial to use an operator because it encapsulates some DBA knowledge.
- Cloud-based vendor lock is not Ok. I mean, this is the Fosdem conference, after all.
Effective management of Kubernetes resources for cluster admins
This was a talk on Kustomize.
I’ll be honest with you: I don’t get Kustomize. I understand that Helm is hard and Go Templates are horrible. But each time I hear about Kustomize, folks promise an easy way of managing stuff and end up describing a bunch of override layers.
Yet, if you like the tool, you can find some guides on how it’s used in RedHat and how can you improve your operations with it.
Fosdem 2023 [Sunday 5th of Feb]
Practical introduction to OpenTelemetry tracing
A nice demo on how easy is it to adapt OpenTelemetry in your application with a demo for a couple of different languages: Java, Python, and Rust.
So, if you have a distributed system and you don’t gather traces, you definitely should start doing it!
Adopting continuous profiling: Understand how your code utilizes CPU/memory
I wanted to write about continuous profiling on CatOps some time ago but didn’t.
The idea is to take snapshots of your app periodically instead of running a full-fledged profiler. So, you can observe what your app is doing without much overhead for profiling. Also, you can do that in production.
However, this talk was mostly about a new Grafana product for continuous profiling - Phlare.
Inspektor Gadget: An eBPF-Based Tool to Observe Containers
Inspektor Gadget is an eBPF toolset to get an idea of what your container is doing. It may provide some useful insights into missing capabilities for a K8s pod and so on.
I’m not sure yet if I ever have a use case for it. I mean, I’m not sure if I ever need to dig so deep. But, it’s nice to know that such a tool exists and have it in your toolbox.
Best Practices for Operators Monitoring and Observability in Operator SDK
If you have ever written a Kubernetes operator, you probably know this all already. Moreover, the points of this talk are also listed on the “Best Practices” page of the Operator SDK documentation.
However, if you are up to writing your first operator, those points can be very valuable.
Open Source Software at NASA
This is one of the keynotes. The talk is about how NASA uses open source to explore the universe as well as fly a copter drone on Mars.
Also, this presentation has a lot of amazing images in it!
Configuration Management Camp 2023 [Mon-Wed 6-8 Feb]
It is much harder to share things from the CfgMgmt Camp because many videos are not available yet. But, there are some already.
So, this will be a short list with some of my impressions.
What if Infrastructure as Code never existed?
A keynote by Adam Jacob. He’s a charismatic speaker, which is what every keynote needs. It was about a new concept of Infrastructure as a Model instead of the usual Infrastructure as Code. TBH, I haven’t fully comprehended the concept. Also, the project is fairly young. So, it would be nice to see a demo of it someday.
Choosing an Infrastructure as Code Solution
A talk on types of IaC that exist in the wild. The talk is from Pulumi folks, so it’s a little bit biased, but still a nice talk.
Set Up a “Production-Ready” Kubernetes Cluster in 5 Minutes
Yet another opinionated Kubernetes setup. I liked this picture that gives you an overview of components that you may want to have in your cluster. As well as some tools that cover those areas.
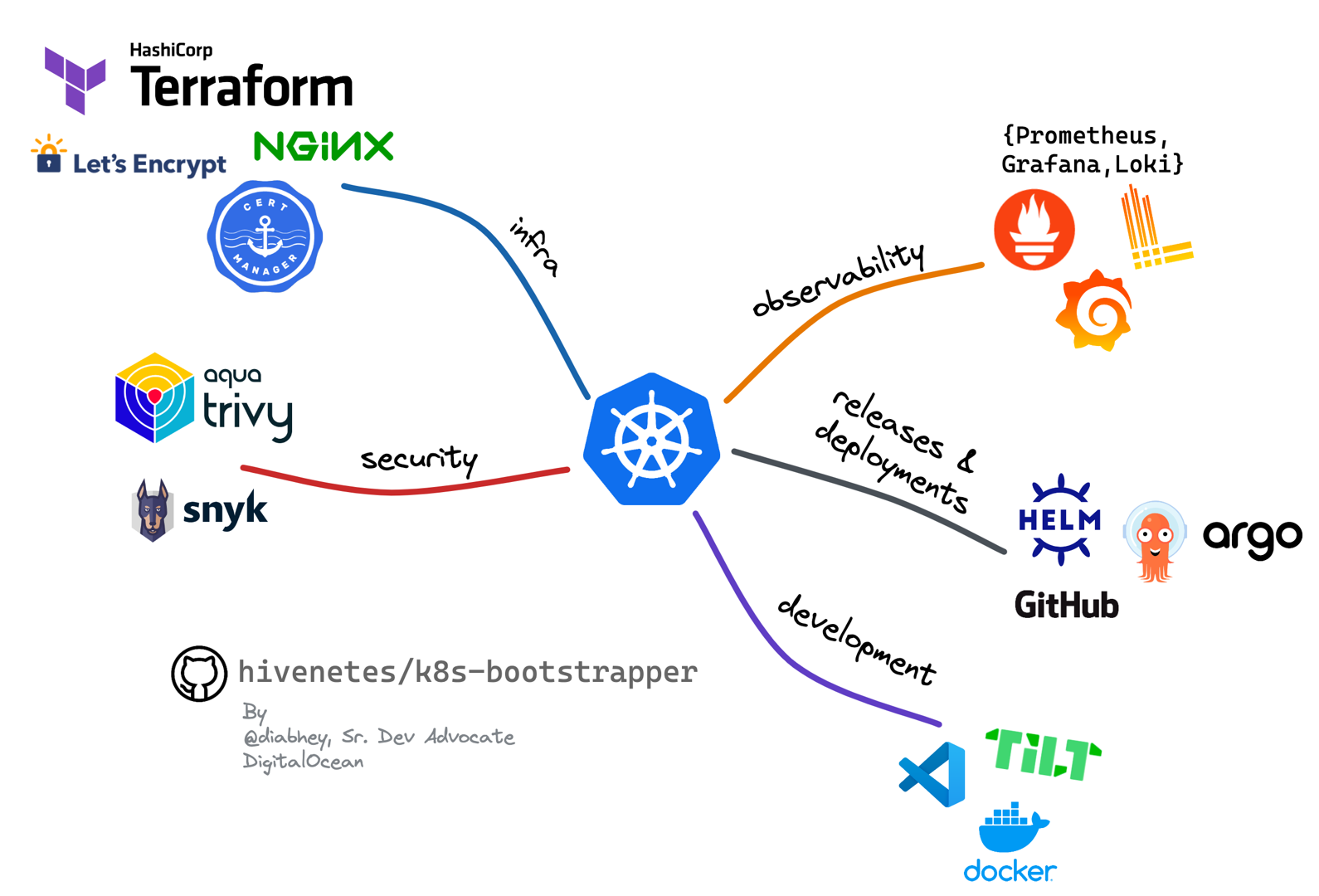
Video:
Unknown unknowns and how to know them
In the end, this is a presentation of a tool that allows you to “map” your infrastructure as an investigation goes on. There are some interesting points in this talk:
- There is no such thing as a “root cause”, it’s always a combination of factors.
- Unknown unknowns is the most common cause of incidents. You cannot test or monitor things you have no idea about.
- It’s nice to know in advance what impact a potential change would have. Therefore it’s nice to have a way to “query” your infrastructure.
Video:
Open Policy Agent: security for cloud natives and everyone else
Just a very basic introduction to OPA (Open Policy Agent). I already have some articles about OPA on CatOps, in case you want to dive deeper. I won’t duplicate them, you can search for them there.
The interesting part was a new product by Elastic - Cloudbeat. It allows you to scan your infrastructure against CIS Benchmarks and is powered by OPA.
Efficient Kubernetes scaling using Karpenter
A nice demo of Karpenter - a relatively new autoscaler for Kubernetes. It’s backed by AWS and currently works only with AWS. This is probably the most powerful all-in-one scaling solution on the market (if we don’t account for some proprietary tools). Unfortunately, there’s no video available. I’m not even sure if that room was recorded.
Have you hardened your Kubernetes infrastructure?
The last talk was on the first day of the conference. The content was good. Some practical bits of advice on how one can harden their K8s clusters and make workloads that are running there more secure. Also, slides for this talk are available. So, you can easily get this content there.
CUE: a Glimpse into the Future of Configuration Engineering
I have also written about CUE on CatOps already. Shortly: one ring to rule them all. The idea is that there’s a single language to define data structures. And it has some syntax sugar (otherwise, this is a superset of JSON). Will it be widely adopted? Will see, it has some adoption already. However, it’s not clear how the people behind CUE are going to secure funding for their project.
Video:
10+ years experience with IDPs (Internal Developer Platform) to enable fast-growing companies
So, this was a good one! Probably, one of the best talks of the conference. Yes, the speaker may be lacking charisma a bit (also, it looks like he doesn’t like K8s for whatever reason :P). Yet, the content is great. I would summarize the main idea in these points:
- An Internal Developer Platform can boost your company’s productivity.
- No, you cannot simply install Backstage and consider it done.
- Yet, you can build a solid platform with the things you have: it’s all about UX and contracts, not some fancy tools.
Video:
Kubernetes & The Myth of Cloud Portability
This a nice theoretical “case study” of how to migrate a business from AWS to GCP. Some good points:
- Each challenge has more than one solution.
- If one needs portability, one has to optimize for this, which may increase operational costs.
- Also, the talk mentioned some nice tools that I never heard of before. For example, Dapr - is a framework for cloud-agnostic access to queues.
From Monitoring to Observability: eBPF Chaos
This talk wasn’t recorded. You can find the slides here. So, this was about eBPF (obviously) and many things one can do with that both good and bad. Some tools mentioned during this talk (in no particular order):
- Inspektor Gadget. Mentioned here already.
- Caretta - a tool to automatically build a service map from a Kubernetes cluster.
- Coroot - eBPF based observability tool.
- Chaos Mesh - chaos engineering platform for Kubernetes.
- Chaos Toolkit - a toolkit for chaos engineering experiments.
- Pixie - an observability tool by NewRelic.
- Xpress DNS - experimental XDP DNS server written in BPF.
Well, that’s all, folks! The third day of the Configuration Management Camp Conference (or the fifth day overall) was for workshops. I listened to a bit about how to build and ship Pulumi packages. But, since I’m not using Pulumi it was not particularly valuable to me.
I hope you have enjoyed this recap! The next conference I plan to attend will be KubeCon Europe 2023. If you go there as well and want to have a chat, don’t hesitate to ping me. My contacts are here.
