This is the second part of a series of articles regarding Kubernetes backups. You can find the first part about Velero tool here.
Why Backup Kubernetes?
In the previous part I provided a brief overview of the backup & restore tool for Kubernetes called Velero. Now, I would like to talk, why backup your cluster at all?
What makes a cluster?
A typical production cluster has a three-layer structure. There are Kubernetes components themselves. There are plugins that ease your operations e.g. ingress controllers, admission webhooks, etc. I will refer to them as “core plugins” from now on. At the end of the day, there are applications - actual workloads that make your company’s money.
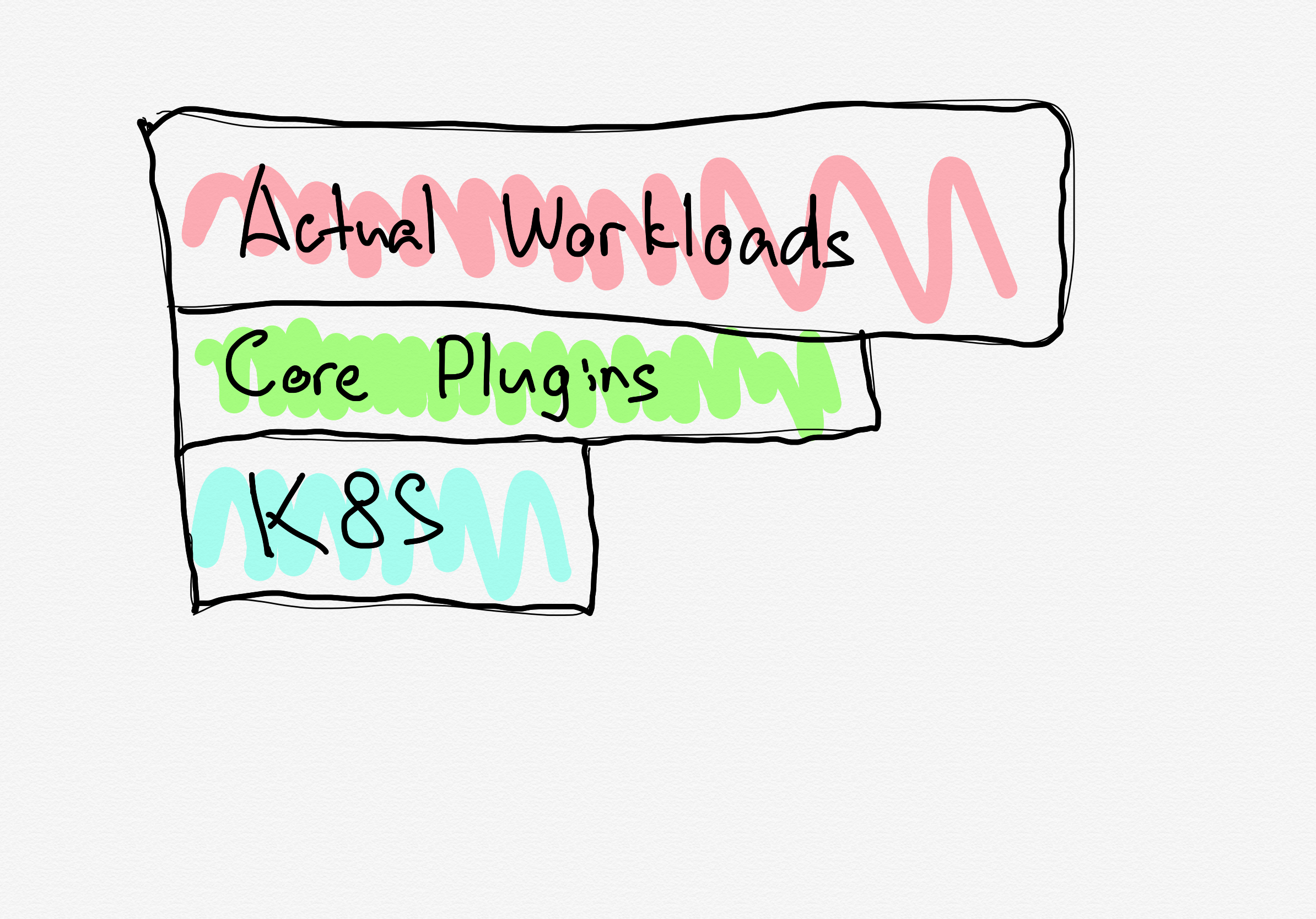
cluster layers
Those layers are usually managed separately and have a different lifecycle. For example, you can use a managed Kubernetes cluster, then install core plugins with Helmfile, and manage your production services using Argo stack. The lifecycle is different for each layer in this scheme. Kubernetes has a few major releases each year with occasional patches. Core plugins may have releases each month or so. Finally, you may release your end-user applications daily or even a few times a day. It means that the procedures for core components and your apps are different, even if you use the same toolset.
Let’s Talk About Automation First
We have figured out that each layer has its own lifecycle, but there is one more thing to talk about before we switch to backups - automation.
Automation is a crucial part of any modern infrastructure. From good old configuration management to modern cloud CDKs, the industry was always striving to automate as many routines as possible. Phrases like “A good sysadmin has nothing to do”, - or “To automate yourself out from your job”, - didn’t appear out of the blue.
Also, each cluster layer may have a different degree of automation. Of course, it’s cool, when you can re-create a whole stack with a single command. Unfortunately, I observed very few such configurations in practice. Usually, there is an automated CI/CD process for end-user applications and semi-automated core plugins. Core plugins may use the same delivery tools, but a manual testing process. Cluster rollouts are either handed over to a vendor or presented as a list of documented steps.
Also, each layer accommodates different risks to the whole system. It’s less critical to lose a single microservice than have an issue with the ingress controller. At the same time, it’s easier to redeploy an ingress controller, rather than remediate a cluster after an unsuccessful upgrade.
The less automated is a part of the system, the more important a backup for that part would be.
But What About Backups?
Finally, we can talk about backups! First of all, any backup is a snapshot of a state. In regards to a Kubernetes cluster that’s usually a state of ETCD (I’ll leave behind stateful services in this article). From this point of view, there is no difference between core plugins and user workloads. Those are the same Kubernetes abstractions. So, the second and the third layers are kind of combined in a “bare backup”. At the same time, a cluster itself is outside of this scope. And this is usually the least automated part! Thus, investing in cluster automation early on is important. You may end up in a situation when you need to re-create a cluster from scratch. And a backup for cluster workloads won’t help here! Moreover, cluster automation can help to expand into different regions.
It doesn’t matter which type of cluster automation do you have. You can use a vendor’s distribution, a cloud service, or create your automation. All these things work similarly efficiently. Although, they require different times to implement and provide a different degree of flexibility.
Once you have automated cluster rollouts, you can be sure that you have a place to restore your backup, if a cluster-wide disaster occurs.
Deployments and States
Each deployment changes the cluster state. It doesn’t matter if that is a deployment of a core plugin or a business application.
Backup tools keep snapshots of a state. That makes perfect sense when there are no other references of the same state. In other words, no more sources of truth. Here I assume that the actual state from ETCD is lost or corrupted, so you cannot restore it from another cluster. In this case, it’s crucial to have backups in place. But what if there is more than one source of truth?
The biggest problem with backups is that they become inconsistent in some time. Things keep changing, developers deploy new app versions, and so on. Involuntary rollback of a production service is a fair price to pay to speed up recovery. Though, is there anything that promises better consistency of expected and actual states? Well, GitOps does that!
With GitOps you store your state in Git. Then you refer to this declarative configuration to reconcile the cluster. This approach works well with both core plugins and production workloads. GitOps alongside with automated workload backups may result in a kinda “split-brain” situation. There may be new changes in Git, but a new snapshot is not taken yet. If you encounter a problem, would you refer to information from Git or your cluster backup?
This brings us to a logical conclusion: backup only those states that will be lost in case of a disaster.
There’s no reason to have backups for sake of backups. Moreover, backups should be validated from time to time. You need to know that they’re restorable and how to restore them. Keep in mind that Kubernetes backups are not quite the same as good old disk snapshots. You won’t have all your services recovered immediately! You will have your desired state recovered and a scheduler will do its best to fulfill that. So, eventually, your services might be fully recovered. Thus, it makes a little difference which tool populates the state: Argo (for example) or Velero.
tl;dr
Instead of a conclusion, I put a tl;dr that summarizes everything I’ve just said.
- Clusters are like ogres, they have layers. Each layer is likely to have a different lifecycle, be automated to a different degree, and possess different reliability risks to the system as a whole.
- Invest into cluster automation early! It is not just a lifebuoy in case of a disaster but also helps to easier expand to another geographical region.
- Backup only those things, whose state will be lost in case of a disaster. If you have a state elsewhere, like in Git, don’t back up those things at all. Let a GitOps tool figure that out. If you have a mixture of CD tools, backup only those things that are installed imperatively.
- I prefer to invest time and resources into functional GitOps in Kubernetes environments, rather than backups and their validation. This is just my opinion and I’m fully aware that this is way harder than simply install Velero into a cluster.
- Or rather 4.5. It’s perfectly fine to have backups before you have GitOps in your organization. In any case, it’s much better than nothing.
I hope, you enjoyed the reading! Comments in this blog are disabled forever. If you have any questions or ideas, feel free to reach me out in Twittter or Telegram!
Happy New Year, y’all!