Kubernetes Survey Results
Not so long ago, I created a survey to understand how people manage their Kubernetes clusters. I got more than a hundred responses from Telegram, Reddit, Twitter, and DOU, 102 to be precise. Now, I am ready to share it with you!
You can find all the raw data via this link.
This text is also available in Ukrainian.
A backstory (skippable content)
After, I wrote the article about Kubernetes backups - Why backup Kubernetes?, I got a few questions about the cluster topology we use. Especially on the “cluster as cattle” concept and technical struggles associated with it. I started writing a follow-up article on that topic, but then I realized that my view is limited by the experience at just a few companies. Thus, I decided to ask people about how they manage their clusters. So, here we are.
I’m still going to write something about the “clusters as cattle” concept, but first I want to share the insights from the survey.
Cluster Types and the Number of Clusters
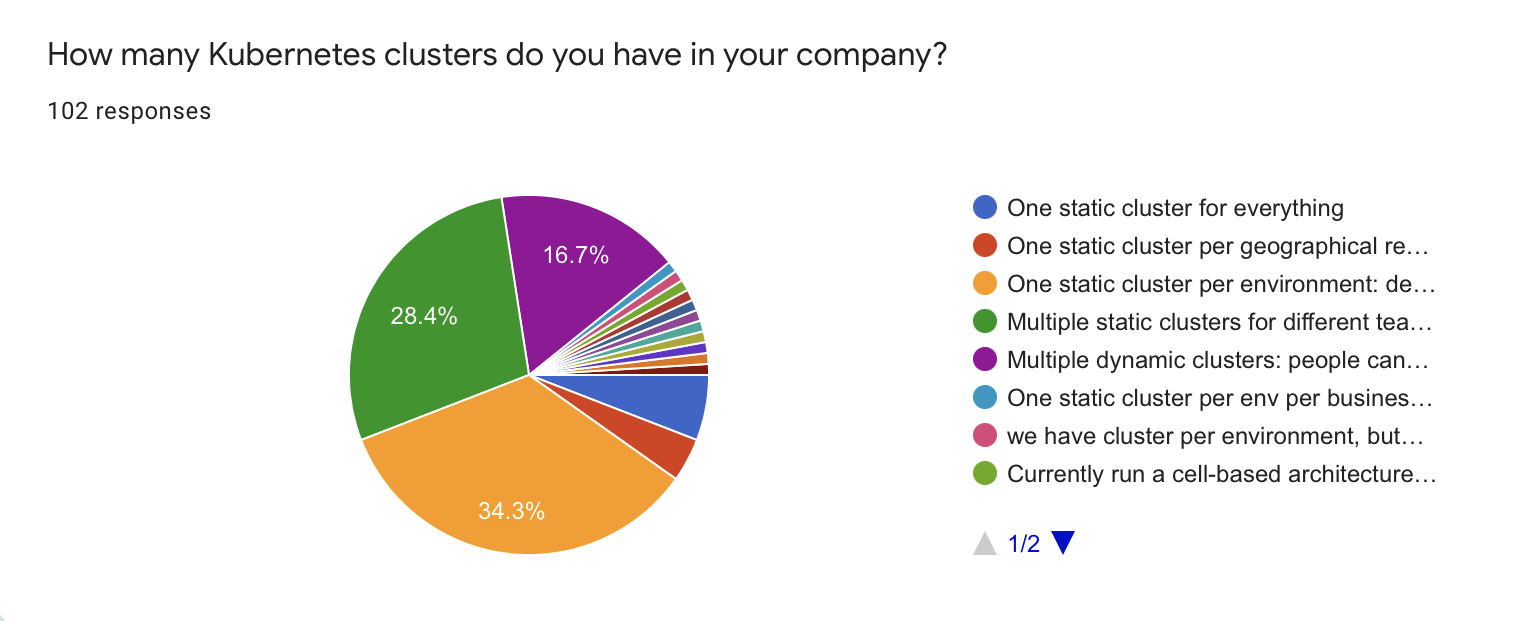
The majority of respondents (~80%) use static clusters. 35 of them (34.3%) use one static cluster per environment and 29 (28.4%) use the different static clusters for different teams.
17 respondents (16.7%) use dynamic clusters that they can spin up on-demand. A few respondents mentioned that they are heading towards dynamic cluster management, but they are not quite there yet.
The maximum number of clusters that was mentioned is 200
Kubernetes Distributions
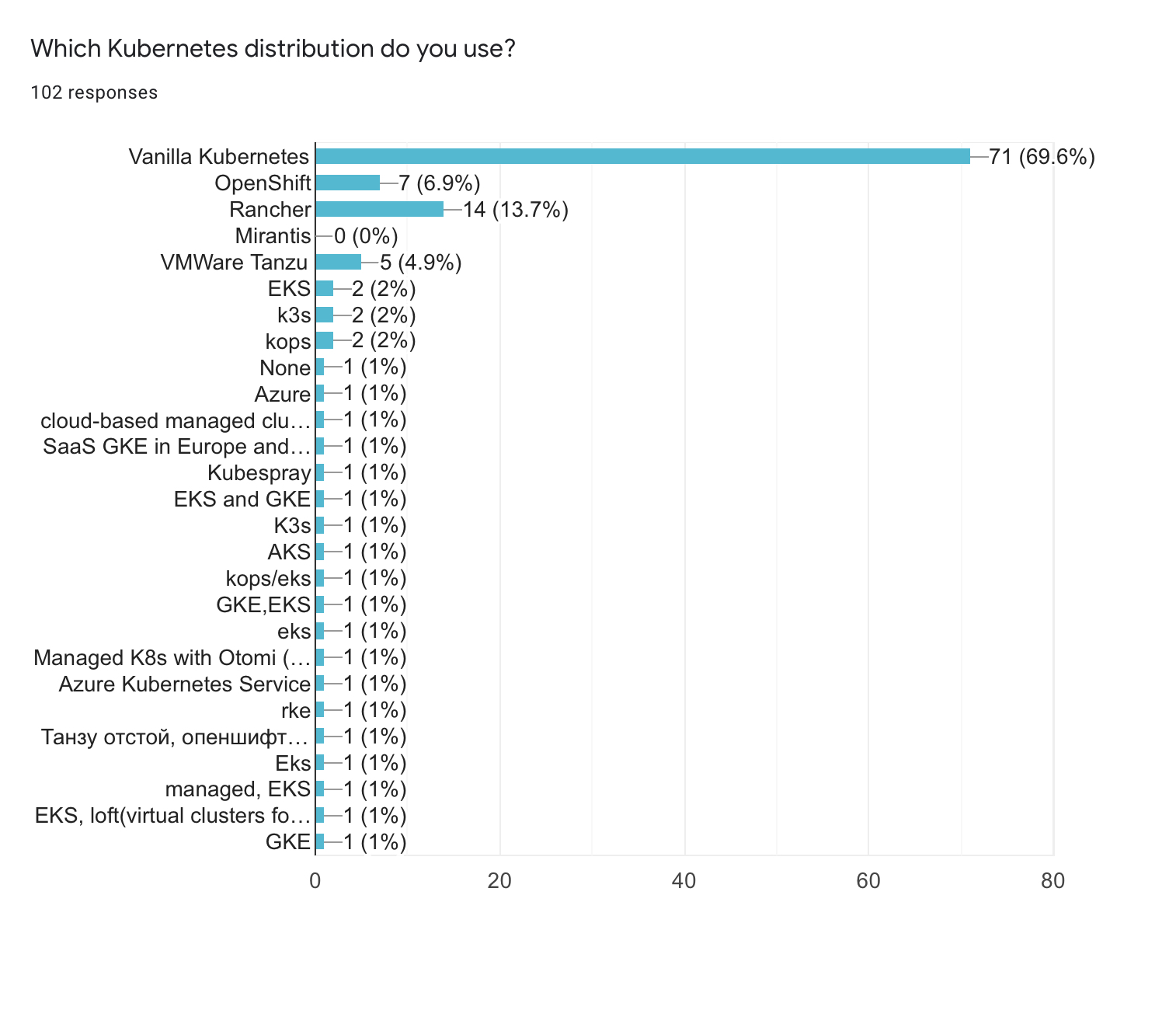
- The vast majority of respondents (more than 70%) are using vanilla Kubernetes, including the managed solutions
- Rancher’s distributions are the second choice with around 18% of users, including the k3s distribution
- Some people are using the combination of different distributions e.g. managed services in one market and self-hosted RKE in other
- OpenShift is the 3rd choice with around 8%
In general, I expected more users of OpenShift out there. However, this is a tough question: what makes a Kubernetes distribution? One can argue that managed clusters like GKE or EKS have features on top of the vanilla version, which technically makes them a separate thing. Also, Rancher has several products. Thus, gathering all of them under a single umbrella likely affected the results of this question.
Managed vs Own Clusters
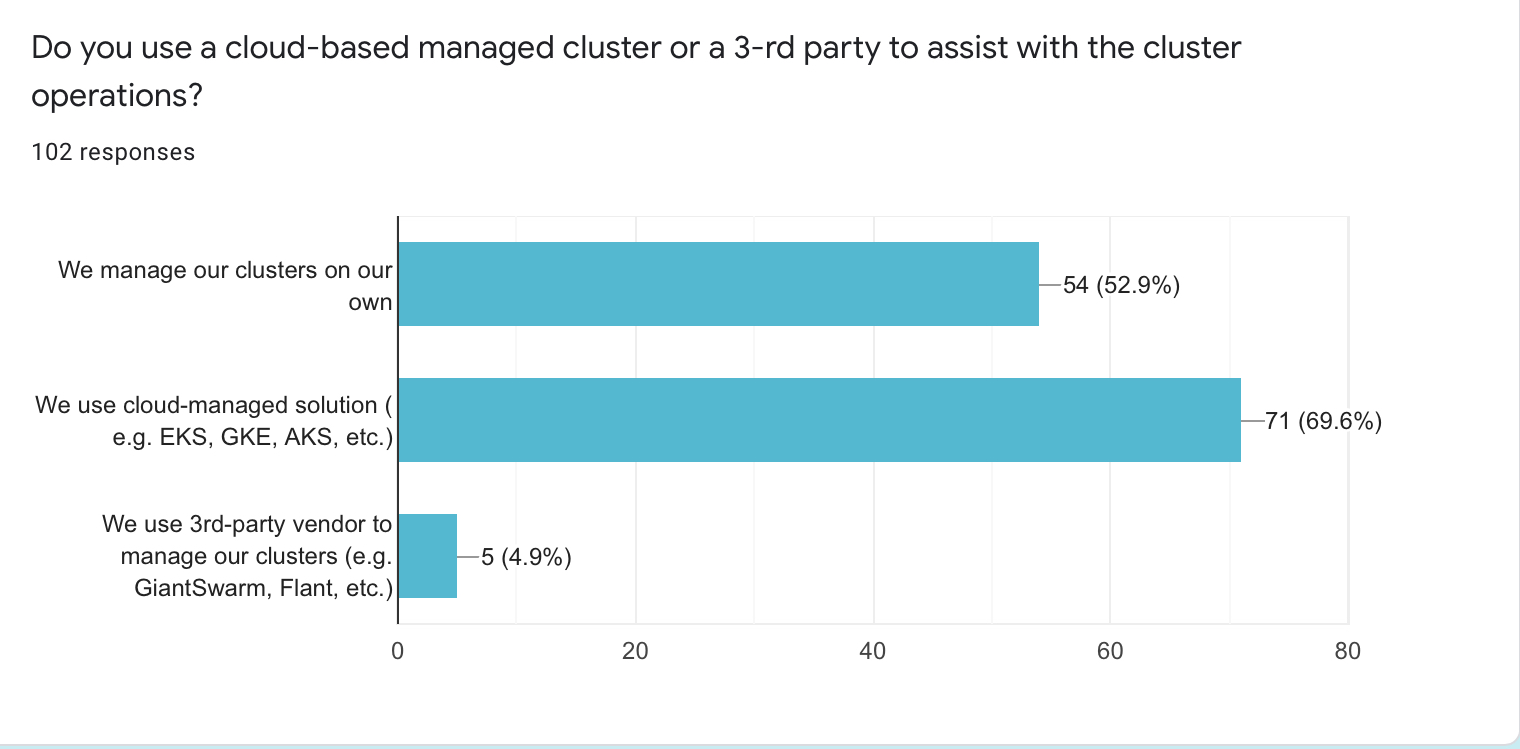
- 71 respondents (69.6%) are using cloud solutions to run their clusters
- 54 (52.9%) manage clusters on their own
- 5 persons (around 5%) have outsourced cluster management to a 3rd party provider
- The total number is more than 100% because some people use a mix of self-managed and cloud clusters
- A popular reason for having a mix of self-managed and cloud-managed clusters is a multi-cloud or hybrid cloud setup
- Another popular reason is an ongoing migration from self-managed to cloud clusters
- Another interesting reason for having a mix of different cluster modes is the way of working for a company. The company has to integrate its software for different customers. Thus, they test it in various configurations.
Overall, there is a tendency to move to cloud-managed clusters. A few respondents mentioned that outsourcing cluster management to a service provider removes the operational headache from them and allows teams to focus on other features.
I expect the number of cloud clusters users to increase in the upcoming years. Self-managed clusters won’t go away, though. Not everyone is using public clouds. Also, some businesses have specific requirements for control of the cluster internals.
Some other insights:
-
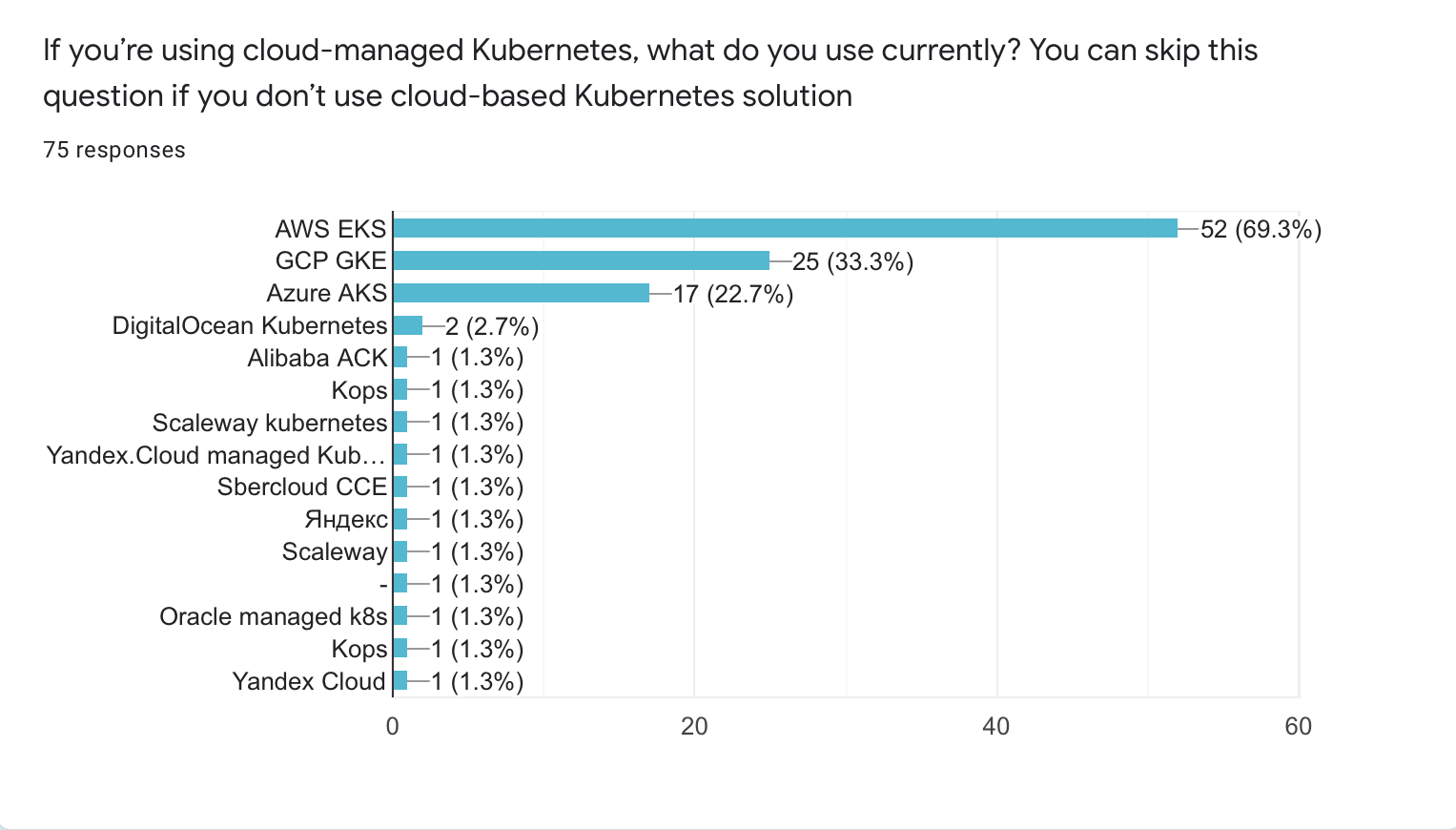
AWS remains the most popular cloud provider, at least among people, who participated in this survey.
-
GKE is used by 25 people (33.3%)
-
AKS (Azure) is third with 17 users (22.7%).
Cluster Versions and Upgrade Dynamic
Taking into account the trend for cloud solutions, it’s safe to assume that many people use whatever Kubernetes version is offered by their cloud provider. 35 participants (34.3%) answered just that.
I must mention that cloud providers usually support multiple versions of Kubernetes. Therefore, I had to design this question better. Let it be a lesson for me.
Other numbers:
- 26 respondents (25.5%) use a mix of different Kubernetes versions
- 14 (13.7%) use an older minor version, which is still maintained
- Using “the latest minus one” version is another way of working, which is adopted by 10 out of 102 respondents (9.8%)
- 6 respondents (5.9%) are keeping up with the latest patch version once it’s available
- Another 6 respondents (5.9%) are using an unmaintained version of Kubernetes (<1.20 at the time of the survey).
As I mentioned earlier, I should’ve designed this question better. It doesn’t provide many insights into the real situation with Kubernetes version distribution. Although, I find it amusing that answers “the latest version” and “the outdated one” have the same number of votes.
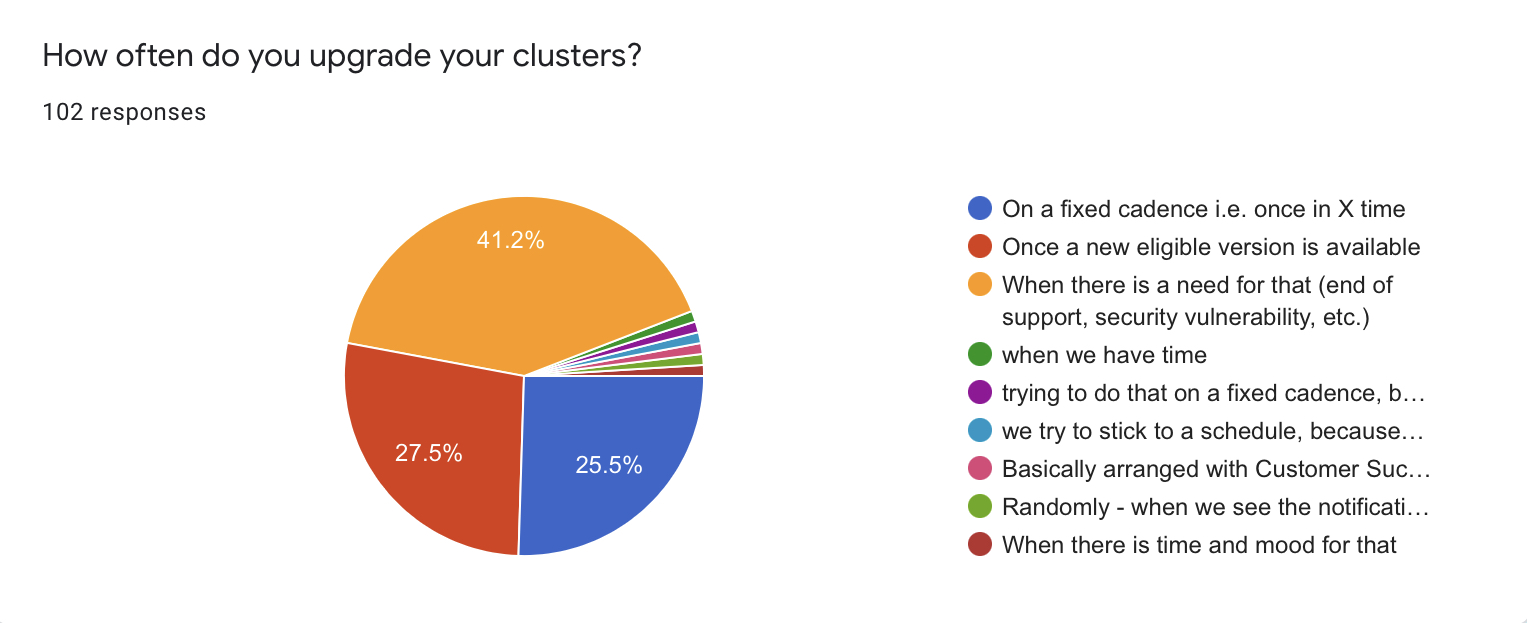
Almost 3/4 of respondents do not have any fixed cadence for cluster upgrades and do that when required. 26 respondents (25.5%) stick to the fixed upgrade cycle.
Among the popular reasons for upgrade:
- Necessity: version EOL, open vulnerabilities, etc. - 42 (41.2%)
- Availability of a new version - 28 (27.5%)
- Some people have answered that they upgrade when they have time
- One person mentioned that they want to upgrade clusters on a fixed cadence, but it’s not always possible
- One person mentioned that they first have to arrange upgrades with their customers
There is a catch in this question, though. As you can see, the majority of people do not try to create their own upgrade schedule. Yet, there is still a high percentage of respondents, who keep up with new versions. Thus, they implicitly follow the official Kubernetes release cycle.
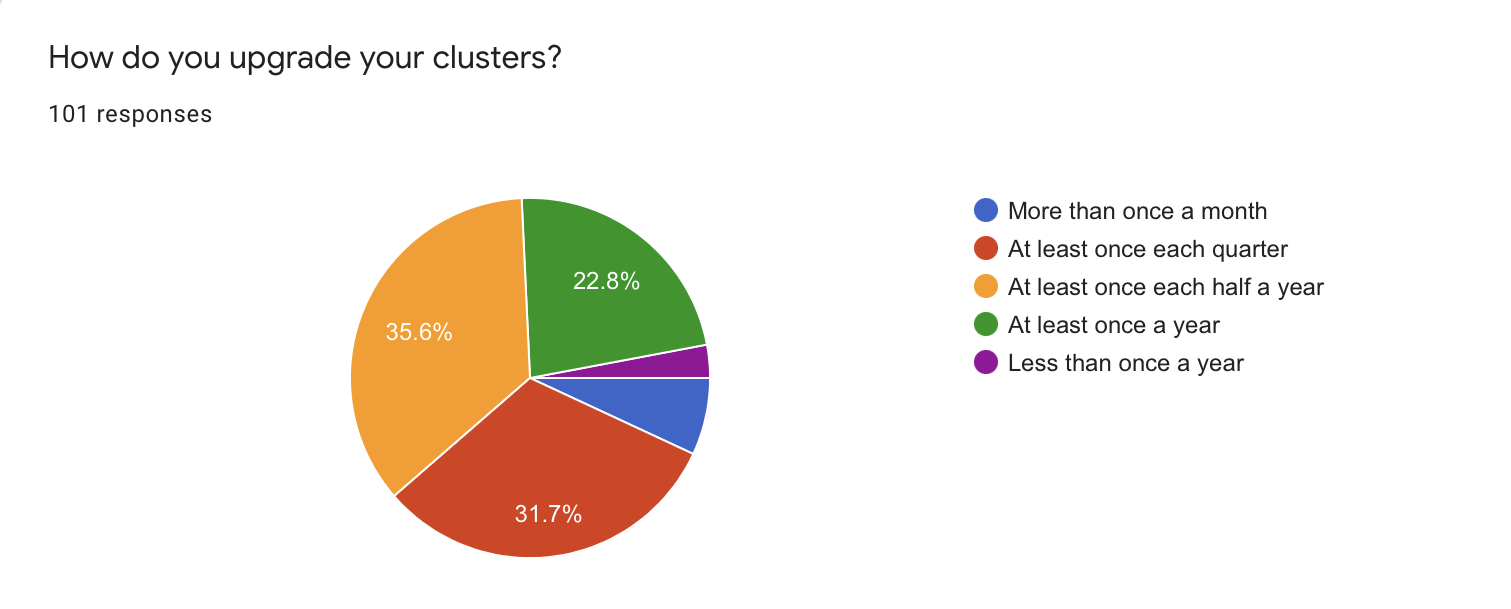
I made an obvious mistake in the wording of this question. Of course, it should have been something like “How often do you upgrade your clusters?” or something similar. Shame on me.
As you can see, there is no clear common practice here.
- 36 respondents (35.6%) upgrade their clusters at least once in half a year
- 32 respondents (31.7%) do that at least once a quarter
- 23 (22.8%) - at least once a year
- Only 3 persons upgrade their clusters less often than once a year
- 7 people (6.9%) do that at least once a month
It would be interesting to keep an eye on this metric in dynamic. On one hand, the adoption of automation and cloud clusters should increase the frequency of upgrades. On another hand, the frequency of cluster upgrades may go down because of the last year’s change in Kubernetes release cycle.
Cluster Upgrade Automation
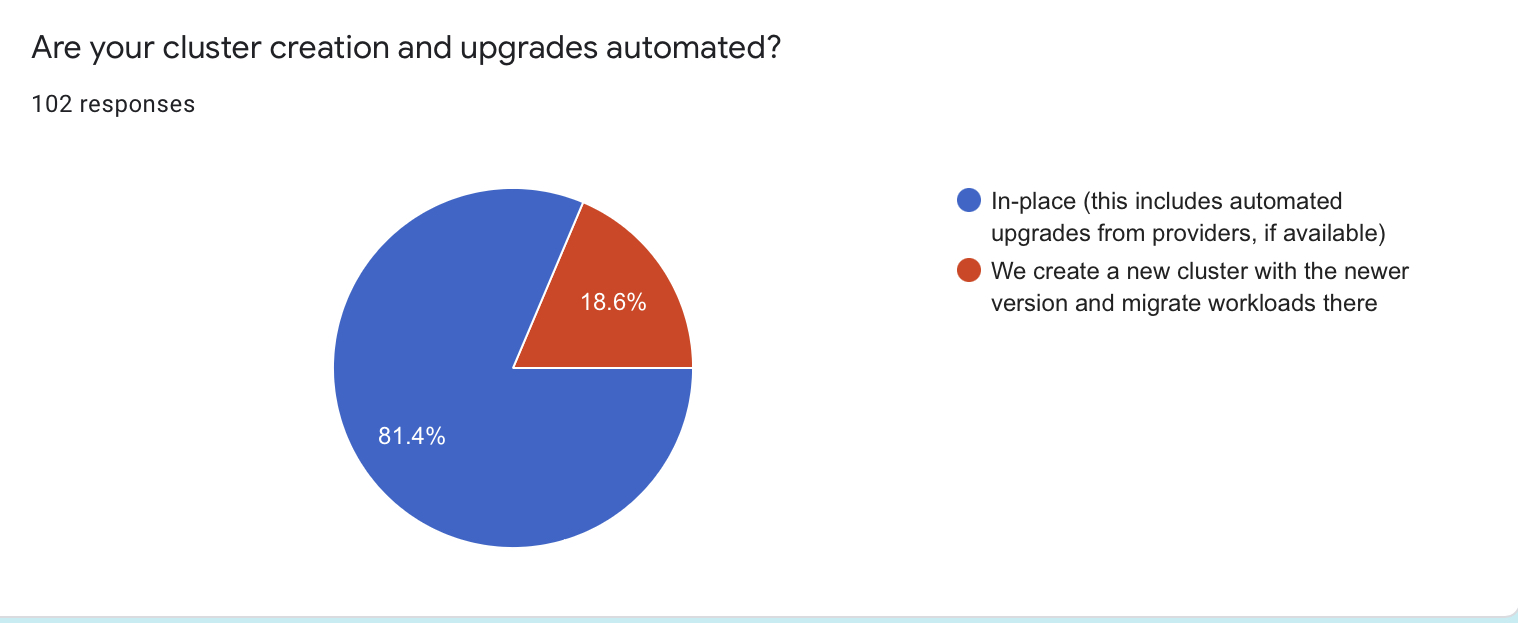
The vast majority of respondents (83 / 81.4%) upgrade their clusters in place. It means that they apply an upgrade on top of the running cluster.
Others (19 / 18.6%) create a new cluster and migrate their workloads there during cluster upgrades.
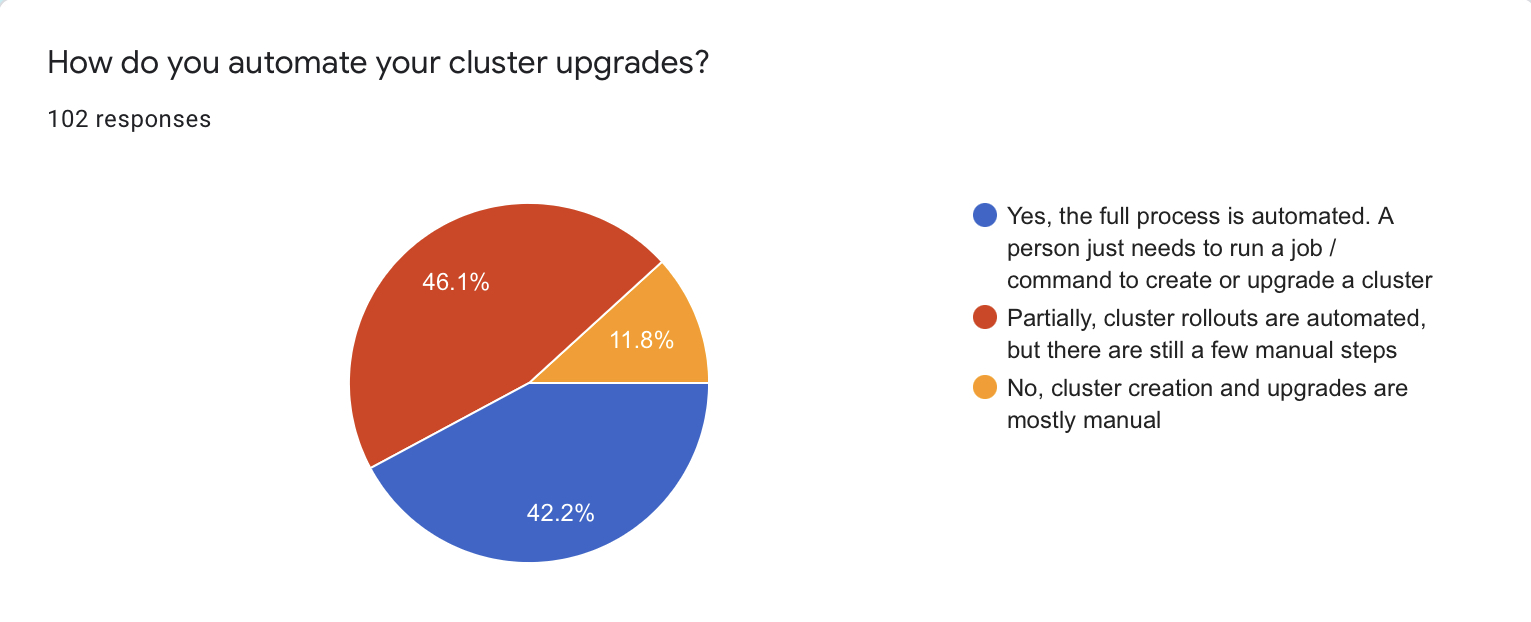
Speaking of automation, the majority of people (90 / 88%) have their cluster upgrades automated at least to some extent. 42 respondents (42.2%) have said that they have automated the whole process. Thus, one can execute a command or an automation task to upgrade a cluster. Only about 12% of respondents still go through the manual process for cluster upgrades.
This is another metric that would be super interesting to observe in dynamic. I assume that the “manual part” will decrease in time. I don’t think that 100% of people will have their cluster operations fully automated. Sometimes “good enough” is the way to go.
Although, it means that cloud vendors have room to improve their cluster offering. So their customers can select the “fully automated” option without hesitation.
I messed up with the question wording again. I’m sorry for that.
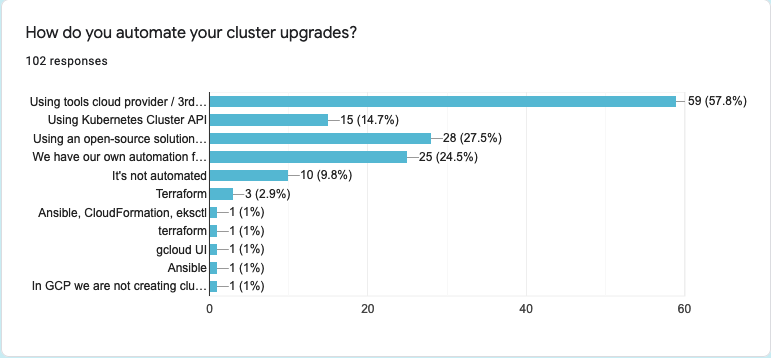
- 59 (57.8%) of respondents use their cloud provider APIs, which correlates with the trend of cloud cluster usage perfectly
- A surprisingly high number of people - 25 respondents (24.5%) - use their in-house automation tools
- Open-source solutions remain the main popular choice for 28 (27.5%) people, who participated in this survey
Another interesting take is that 15 people (14.7%) use Kubernetes Cluster API, which brings Cluster API on the 4th place for automation of choice.
Core Components
As I said many times, no one needs a bare Kubernetes installation. The ecosystem around it makes it a special and widely adopted framework for building platforms. From now on I would call all the software that helps running production workloads the “core components”. This name captures the nature of these plugins very well.
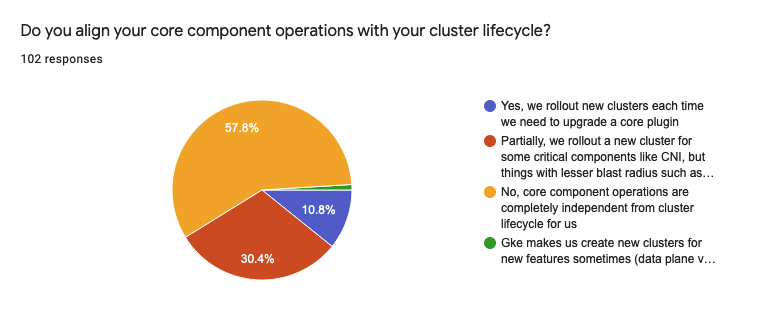
- More than half (59 / 57.8%) of the respondents do not align cluster upgrades with components. It means that a cluster lives its own life, while components are managed separately
- 31 respondents (30.4%) align their cluster upgrades with upgrades of some critical components. Things like CNI are aligned with cluster rollout, but other lesser critical plugins are independent
- 11 (10.8%) rollout new clusters each time they need to upgrade a core plugin.
Also, one person mentioned that GKE makes them create a new cluster for some components upgrades. This is an interesting insight into GKE operations. At least for me, ‘coz I’m not very familiar with GCP, to be honest.
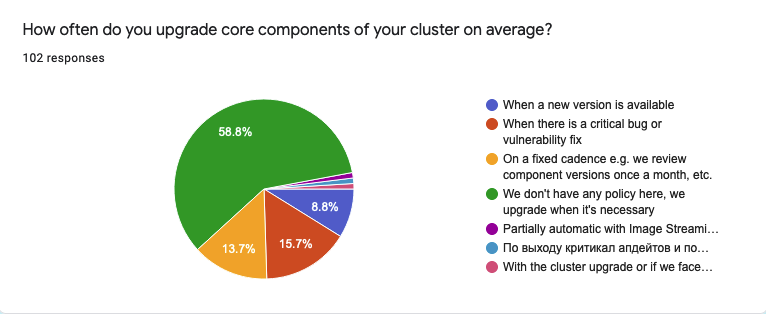
Speaking of the core components upgrade cadence.
- The majority of respondents (60 / 58.8%) don’t have a fixed schedule and upgrade their core plugins when it’s necessary
- 16 people (15.7%) apply upgrades only when there’s a bug fix or vulnerability
- 9 people (8.8%) when a new version is available
- One person mentioned that this process is semi-automated in their company with the GitOps approach
On another hand, 14 people (13.7%) said that they have a fixed cadence to revisit core components’ versions. Also, one person mentioned that they have a monthly cadence, but they also check for critical bug fixes and open vulnerabilities. Thus they upgrade certain core plugins more frequently.
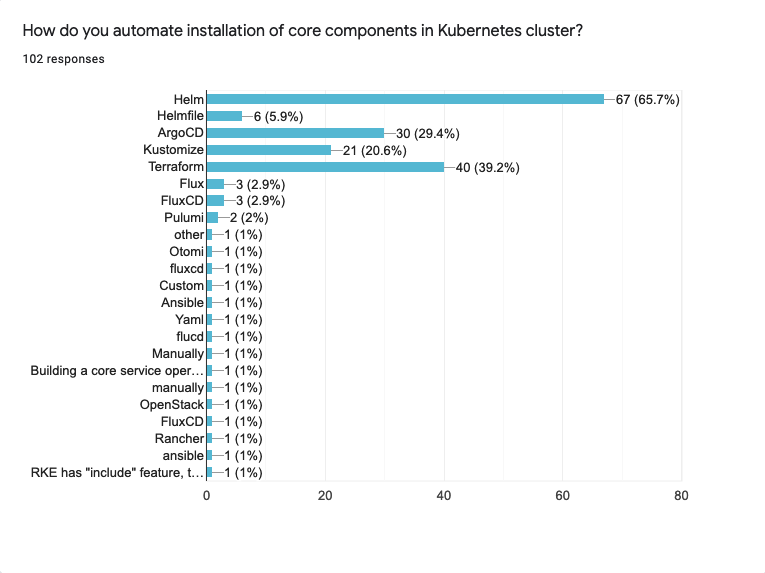
Speaking of tools.
- Helm is the tool of choice to manage core components for 67 people (65.7%)
- Terraform has second place with 40 answers (39.9%)
- ArgoCD and Kustomize got 3rd and 4th places respectively with Argo being a little bit more popular: 30 (29.4%) vs 21 (20.6%)
It is expected that this question has a long tail of “Other” responses. There are quite a few technologies mentioned there e.g. Flux, Ansible, pure YAML, a custom operator, etc.
Blue/Green Upgrades
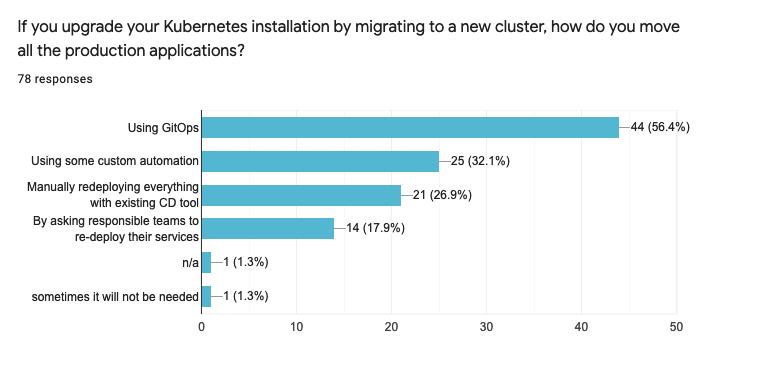
- Around the half of the people (44 / 56.4%) who upgrade their clusters by creating a new one and migrating there, use GitOps
- Another 25 respondents (32.1%) built their custom automation
- 21 participants (26.9%) manually redeploy everything each time they need to migrate
- 14 operators (17.9%) have mentioned that they need to ask responsible teams to redeploy their things as a part of the procedure
- Also, one person mentioned that sometimes a redeploy is not required. Please, if you read this, reach out to me, I’m genuinely curious about such cases
Backups and Disaster Recovery
Since the series of my Kubernetes articles start with backups, this topic is particularly interesting to me.
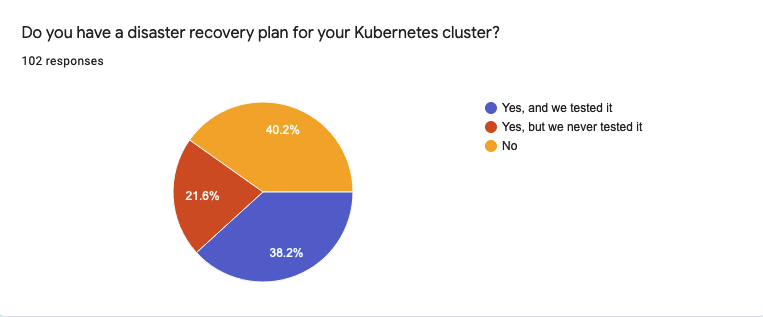
- So, only 39 (38.2%) of respondents have a disaster recovery plan that is tested. Unfortunately, I missed the opportunity to clarify if this is a part of a routine, or this plan was tested during an incident
- 22 people (21.6%) have a disaster recovery plan, but never actually tested it
- 41 respondents (40.2%) do not have any disaster recovery plan in place at all
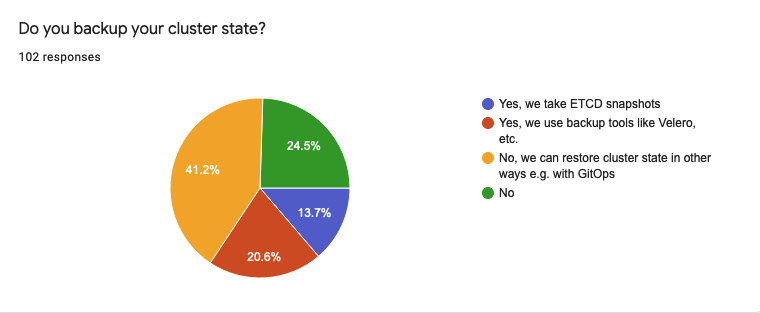
Not everything is that bad, though.
- 42 respondents (41.2%) mentioned that they can restore a cluster without a backup i.e. using the GitOps approach or other methods
- 21 participants (20.6%) use dedicated backup tools like Velero
- 14 (13.7%) take snapshots of ETCD
- However, 25 respondents (24.5%) have answered that they do not back up their clusters at all.
If you compare responses for two previous questions, you can see that 28 (27.5% from total) participants, that don’t have a disaster recovery plan or never tested it, also mentioned that they can restore a cluster using other tools e.g. GitOps.
15 respondents (14.7%) mentioned that they have neither a disaster recovery plan nor cluster backups in place. I would say, these are rather worrying numbers. Cluster issues can occur even with a cloud-managed solution. So, having a plan B is always a good thing to do.
Conclusion and a Teaser to Part II
That’s all, folks! Many thanks to everyone who participated in this survey! I hope this data helps you to understand what your peers do better and refine your operational strategies.
There are a couple of questions in this survey that would be interesting to observe in dynamic. So, please, let me know if you’re willing to spend some time on such surveys in the future. The comment section is disabled in this blog, but you can always reach me in the CatOps chat (in Ukrainian or Russian) or DM me. You can also find me on Twitter. I speak Ukrainian, English, Russian, and a little bit of German. So, you can use any of those languages for feedback (beware: my German sucks very badly. You are warned!).
And one more thing! The title of this section says “Teaser for Part II”. So, here you go! In this survey, I also asked people to share their most painful experiences with Kubernetes. I got a few responses! I want to keep this part strict and “number reach”, though. I’m going to put all the stories you’ve shared in a separate post and release them soon. Stay tuned!